![David Molnar [Update:, PhD]](https://www.srcf.ucam.org/~dm516/wp-content/themes/twentyeleven/images/headers/chessboard.jpg)
Image feature detectors are a common concept between mammalian vision and computer vision. When using them, a raster image is not directly processed to identify complex objects (e.g. a flower, or the digit 2). Instead feature detectors map the distribution of simple figures (such as straight edges) within the image. Higher layers of the neural network then use these maps for distinguishing objects.
In the mammalian brain’s visual cortex (which is at the back of the head, at the furthest possible point from the eyes) the image on the retina is recreated as a spatially faithful projection of the excitation pattern on the retina. Overlapping sets of feature detectors use this as input.
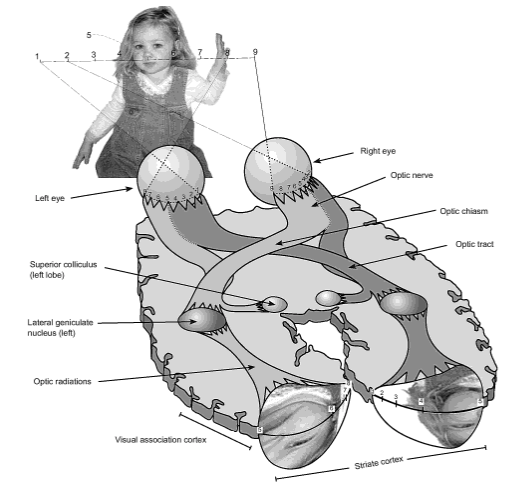
From eyeball to visual cortex in humans. Note the Ray-Ban-shaped area at the back of the brain where the retinal excitation pattern is projected to with some distortions. (From Frisby: Seeing: the computational approach to biological vision (2010), p 5)

How we know about retinotopic projection to the visual cortex: an autoradiography of a macaque brain slice shows in dark the neurons that were most active in result of the animal seeing the image on top left. (From Tootell et al., Science (1982) 218, 902-904.)
A feature detector neuron becomes active when its favourite pattern shows up in the projected visual field – or more exactly in the area within the visual field where each detector is looking. A typical class of detectors is specific for edges with a specific angle, where one side is dark, and the other side is light. Other neurons recognise more complex patterns, and some also require motion for activation. These detectors together cover the entire visual field, and their excitation pattern is the input to higher layers of processing. We learned about these neurons first by sticking microelectrodes into the visual cortex and measuring electrical activity. When lucky, the electrode measured the activity of a single neuron; then by showing different visual stimuli the activation pattern of the neuron could be mapped.

A toad’s antiworm detector neuron reacts to a stripe moving across its receptive field. The antiworm may move in any direction, but only crosswise for the neuron to react. The worm detector, for comparison, would react if the stripe moves lengthwise. Toad at the right side with microelectrode, the oscillogram above the screen shows the tapped feature detector neuron’s activity. (Segment from Jörg-Peter Ewert, Gestalt Perception in the Common Toad – 3. Neuroethological Analysis of Prey Recognition.)
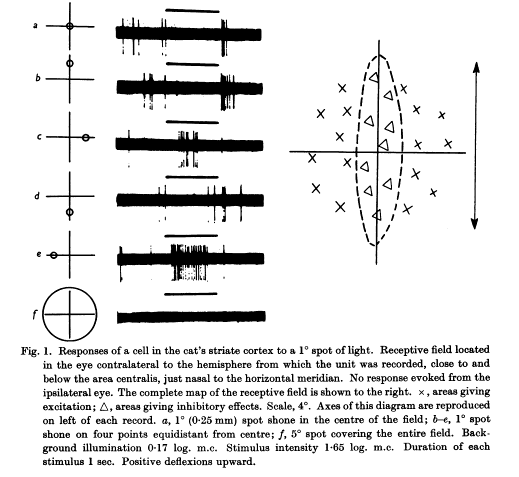
A cat visual cortex neuron that is excited only by light spots at the left and right edges along its receptive field. Light spots at other places are inhibitory: x marks excitation, triangle marks inhibition on the right diagram. (From Hubel & Wiesel, J. Physiol. (1959) 148, 574-591.)
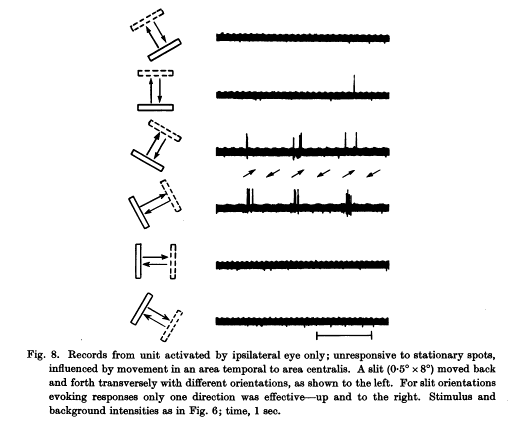
A cat visual cortex neuron that reacts only to a diagonal slit moving up and right. (From Hubel & Wiesel 1959.)
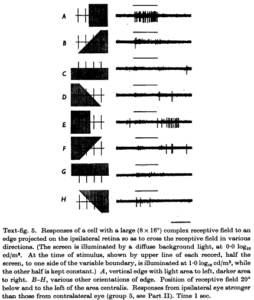
A cat visual cortex neuron that reacts to a vertical edge left or right. Such cells with complex receptive fields do not react to individual spots of light. (From Hubel & Wiesel, J Physiol (1962) 160, 106-154.)
In mammals the combined output of many detectors are analysed by higher layers of the visual cortex for complex object recognition. Sometimes however the raw feature detector output is already good enough for choosing appropriate behaviour. In toads (where feature detectors sit directly in the retina) hunting is driven by a detector for a moving small dark point (a bug detector), and a detector for a lengthy stripe moving longitudinally (a worm detector). Fleeing is initiated by the big scary moving object detector (moving large rectangle) which overrides the worm and bug detectors (videos of great experiments).
How do feature detectors know what to look for? Are they set up 1) completely before birth without input from experience, or 2) are they refined using input from experience, or 3) are they completely the product of experience? (Disregarding that evolution of development itself is a very slow form of gaining experience.) Different species of animals are probably different in details, but at least for cats and primates 1) is not the case. If during a critical period of 3-6 months right after birth these animals are completely deprived of visual experience, then they never develop the ability to distinguish even simple shapes such as rectangles from circles. However, once the necessary structures are in place, they are stable. Visual deprivation later in life does not deteriorate abilities with similar finality. (See here and here for more detailed descriptions of these experiments.)
Each particular feature needs to be seen frequently during the critical period to be well recognised later in life. For example cats only exposed to vertical stripes early on will be later virtually blind to horizontal edges (Blakemoore & Cooper, Nature (1970) 228, 477-478). The opposite is true for cats exposed only to horizontal stripes. In electrophysiological measurements there will be a corresponding absence of feature detector neurons for the unexercised direction. Similarly, cats that see a world only illuminated by very short flashes of light with long dark periods in-between, to suppress any sensation of continuous motion, will have difficulty with analysing motion. Half of the feature detector neurons in these cats respond however to diffuse strobing lights, as the prevalent stimulus during their critical period (Cynader, Berman & Hein, PNAS (1973), 70, 1353-1354). In a different experiment, if the perceived motion during the critical period is always only in one direction, then feature detectors for other directions are less well developed (Cynader, Berman & Hein, Exp. Brain Res. (1975) 22, 267-280).
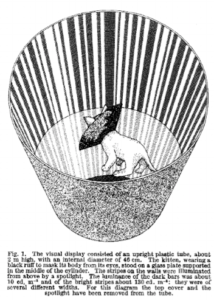
Cat exposed to only one orientation in a striped tube. A black collar hides the own body shape. (From Blakemoore & Cooper, Nature (1970) 228, 477-478.)
As a question for a future post, how do neurons choose what they are sensitive for? They might be set up for recognising random figures and shaping this pattern into actually occurring shapes. There might be also a variety of biases towards shapes, and those cells that find something regularly will survive and refine their target. For comparison, in a slightly different system, binocular vision (in species where both eyes look at the same image unlike e.g. many birds), there are at birth already intertwined anatomical structures that process overlapping visual input from both eyes next to each other (optical dominance columns). If one eye is deprived of vision during the critical period, then the optical dominance columns for the other eye will enlarge at the cost of the deprived eye’s columns, and the cortex for the deprived eye loses processing abilities. (This becomes a problem for those who are born with strabismus and begin to favour one eye.) Similar competition for input or survival might take place also with feature recognisers: either feature types compete for malleable cells, or relatively fixed cells compete for survival. Single-orientation-trained cats seem however not to have large areas without neuronal activity, which might arise through the elimination of never activated neurons. Therefore it seems more likely to me that the orientation specificity of cells is malleable.